

1.はじめに
まちなみは人々の活動によって様々であり、それ故にその「まちらしい」まちなみ画像を創り出すことは難しい作業です。もしこれが可能であるなら、自然な変化により現状のまちなみがさらに良くなるのか、もしくはより良いまちなみのありかたとは何かを検討することができます。前回のAIを用いたまちなみの生成では、飛騨地方のまちなみ写真を特徴量として機械学習を行い、既存のまちなみに類似する画像を生成しました。しかし、前回の方法では生成された画像間をつなぐまちなみを生成できたものの、そのコントロールが難しいという欠点があります。つまり、このまちなみの緑量を増やしたらどうなるのだろう、高層化させたら雰囲気は変わるのか、といった疑問に対して答えられませんでした。
今回は機械学習によって、その「まちらしい」まちなみ画像をうまく創り出せるのか試してみたいと思います。このような分析により、対象とするまちのまちなみらしさや、将来の方向性についてイメージを共有しながら検討できるのではないでしょうか。
2.分析方法
今回の基本的なアイデアは前回と同様に、まちなみの背景にある特徴についてモデル(後に詳しく説明)が正解データなしで自ら学習する手法を採用します。前回、画像生成において高い性能を発揮するDCGAN (Deep Convolutional Generative Adversarial Network)を利用しましたが、上述のように生成したまちなみのコントロールが難しいという問題がありました。今回、このような問題を解決するために、VDB (Variational Discriminator Bottleneck)という方法を試してみたいと思います。
VDBは前回のDCGANと同じような仕組みで、画像生成を行うGeneratorと呼ばれるモデルと、実際の写真とGeneratorが生成した画像を識別するDiscriminatorと呼ばれるモデルの2つを学習していきます(図1)。前回と異なるのは、Discriminatorの学習前にEncoderというまちなみ写真を単純化する役割の作業が追加されることです。この関係は、画家、鑑定士、分析家の関係に似ており、以下、Generatorを「画家」、Discriminatorを「鑑定士」、Encoderを「分析家」として説明していきます。

図1:VDBのイメージ(Peng et al., 2018, Figure 2より改変)
学習が上手くいけば、画家は鑑定士が識別困難なほどに精巧なまちなみ画像を生成し、一方で鑑定士は画家が生成した精巧な画像をも偽物と識別できるようになるはずです。ところが、この2つをバランスよく学習させるのは難しく、どちらかが圧勝してしまうことも良くあります。この困難を克服するために、VDBでは分析家がまちなみ写真を単純化します。写真というデータは非常に複雑なので、そこから直接まちなみの特徴を取り出すことは容易ではありません。分析家には、写真のもつ複雑な情報を整理する役割を期待しているわけです。そして、単純化されたまちなみ写真を参照して鑑定士が画像の識別を行います。
VDBのこのような特徴を踏まえて、今回の分析では以下のようなことに挑戦していきます。
1.様々なまちなみの画像をうまく作り出すことができるだろうか?
2.まちなみの写真から、その「まちらしさ」を取り出せるだろうか?
3.その「まちらしさ」を持つような画像を生成できるだろうか?
1は前回の分析と同じですが、今回はいくつかのまちなみ画像をまとめて学習させ、多様なまちなみの生成に挑戦します。2は分析者の結果から、まちなみの写真からどのまちで撮影されたのか予測するモデルを作ってみます。上手く予測できるならば、分析家はその「まちらしさ」を取り出せていると言えそうです。3では、分析家が取り出したその「まちらしさ」を利用して、そのまちらしい画像の生成に挑戦します。うまくいけば、まちの様々な変化を可視化するのに役立つかもしれません。
3.データの収集
データ収集の対象地域は、東京大学周辺の住宅地又は住宅と商業が混在している地域です(図2)。この周辺では様々な種類の住宅が立地しており、東京大学から10分も歩けば全く異なる雰囲気の住宅地にたどり着くことができます。例えば、根津周辺は木造住宅が密度高く立地し、西片周辺では区画整理された閑静な住宅が建ち並びます。一方で、本郷三丁目駅周辺ではマンション開発によって住商混在のまちなみが形成されています。このような3つの地域を比較することで、それぞれのまちなみの特性の差異や、それらを混ぜ合わせた時に得られるまちなみについて新しい発見があるのではないでしょうか。

図2:対象地の地図(オープンストリートマップより作成)
データの収集に際してGoPro10を用い、1秒間に2枚ずつ撮影するように連続写真を撮りました。撮影方法は自転車のかごの部分(地面から約70cm)に専用の機材を用いて撮影用のGoProを取付け、その自転車を20代男性がややゆっくりの速度で押しながら歩きました。写真の構図がなるべく同じになるように、車道の左側の建物壁面から1m前後離れた位置を歩き、天候状況が似ていた9月中の三日間の同時刻に撮影を行いました。根津地区の写真の撮影日時は9月15日10時から11時、撮影地は根津1、2丁目を中心に一部千駄木2丁目、谷中2丁目で、天気はやや雲の多い晴れでした。西片地区の写真の撮影日時は9月25日10時から11時30分、撮影地は西片1、2丁目、天気は雲がまばらにある晴れでした。本郷地区の写真の撮影日時は9月28日10時から11時30分、撮影地は本郷3丁目と湯島2丁目、天気はやや雲の多い晴れでした(表1)。
表1:撮影環境のまとめ

今回学習に使った写真は、例えば以下のようなものです(写真1-3)。



このように、雰囲気の全く異なるまちなみですが、これらを融合させることでどのようなまちなみが生まれるのでしょうか。
4.結果
今回、学習するための写真を各地区で約5,000枚ずつ選定し、少しずつ切り取る位置を変えたものを1枚あたり5か所の写真を作成しました。つまり、利用する写真データは5,000枚×3地区×5か所=75,000枚になります。さらに、各写真を7回ずつ参照して学習したので、計のべ525,000枚の写真を参考に出力画像を生成したことになります。
まず、根津、西片、本郷三丁目の写真を全て入れてVDBで学習し、画像をランダムに生成しました(図3)。これにより、東京大学周辺の住宅地の一般化されたまちなみがわかります。生成された画像をみると、全体的には建て込んでおり、高い建物も一部軒を連ねているような印象です。しかし、一部では戸建てにみえるものや緑量の多いものもあり、生成された画像にばらつきがあるようにも見えます。これは、今回の生成した画像に様々なバリエーションがあるということです。様々なまちなみの画像をつくるという1番目の試みは、うまくいったと言えそうです。

図3:VDBによる画像生成の結果
それでは、まちなみの写真からどのまちで撮影されたのかを当てられるか試してみます。今回VDBに学習させた画像は256(縦)×256(横)×3(色の3原色)=196,608個の値でできています。今回、分析家はこれをたった512個の値に圧縮します。もしこの512個の値からどのまちで撮影されたのかをあることができれば、分析家はその「まちらしさ」をよく整理できたと言えるでしょう。
そこで、まちなみ写真全体の7割を学習用、3割を評価用に分けて学習を行った結果、評価用まちなみ写真の判別精度は根津、西片、本郷三丁目でそれぞれ97.7%、96.1%、96.0%でした。これは非常に高い正答率といえ、分析家はその「まちらしさ」を上手く取り出せていると言えます。
表2:まちなみ写真予測精度の検証

上記は同じ地区内での判別でしたが、他の地域で「まちらしさ」はどのように判別されるのでしょうか。そこで、2018年に安芸市・琴平町で撮影されたまちなみ写真についても、同様の判別をいくつか行ってみました。利用した街並み写真は写真4-6の3枚です。表3の「まちらしさ」割合をみると、根津らしさが高いのは写真4で、のぼりや鉢植えで賑やかなまちなみを反映しているといえます。西片らしさが高いのは写真5で、整然としたまちなみとゆとりのある道路幅員が反映されていると考えられます。一方、本郷らしさが高いのは写真6で、必ずしも都市的な雰囲気とはいえないまちなみです。これは、写真いっぱいまで樹木が写されているため、それを建物だと勘違いして分類されている可能性があります。以上から、2番目の試みに関してはある程度限界があるものの、概ね成功したと言えそうです。



表3:2018年安芸市・琴平町まちなみ写真の「まちらしさ」割合
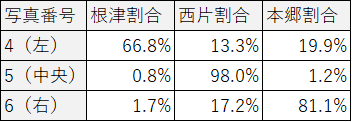
最後に、3番目の挑戦として「根津らしさ」や「西片らしさ」などの割合を考えて画像を生成してみます。ここでは分析家が画家に与える情報から、まちなみ写真がどのまちで撮影されたか予測できますから、画家に与える情報をうまく調整すれば、その「まちらしい」画像を生成できそうです。
分析家に何度も情報を与え、それらの中でもっとも「本郷らしい」「根津らしい」「西片らしい」と予想したものから、画家が画像を生成しました。それぞれ元の写真と比較してうまくまちなみらしさを反映していることがわかります。左図の根津は比較的緑量の多い建て込んだまちなみ、中央図の西片は比較的低層で整然としたまちなみ、右図の本郷三丁目は中層で都会的なまちなみが上手く表現できているように思います。それぞれのまちらしさのバランスも考えてみます。しかし、この方法には限界があり、筆者らがまちらしさの割合を恣意的に数値設定しても、うまく画像を生成できず、その「まちらしさ」を変化させるということは上手くいきませんでした。よって、3番目の試みは今後の課題といえそうです。



5.おわりに
今回、その「まちらしい」まちなみ画像の自動生成ができるのかに着目し、分析を進めました。結果、東京大学周辺の住宅地を参考にして写真撮影を行った場合、各地区の特徴を捉えた画像を生成することが出来ました。特に、今回構築したモデルでのまちなみ判別精度は非常に高く、自動的にそのまちらしさを学習していることがうかがえます。しかし、「まちらしさ」の割合を恣意的に設定して画像を生成することは難しく、今後の課題でもあります。今回利用したデータは、筆者らが自ら撮影したものです。将来、ウェブ上で公開されているまちなみ写真を応用することにより自動的にシステムが構築され、閲覧者はちょっとツマミをいじるだけでまちなみを変化させていくことができるようになるかもしれません。自分の中で何となくイメージしていたものを可視化することで、思いもよらない素晴らしいまちなみを発見できるのではないでしょうか。
参考 1) Peng, X. B., Kanazawa, A., Toyer, S., Abbeel, P., & Levine, S. (2018). Variational discriminator bottleneck: Improving imitation learning, inverse rl, and gans by constraining information flow. arXiv preprint arXiv:1810.00821.
今回使用したプログラムは以下のものを改変して使用させていただきました。厚く御礼申し上げます。
・https://github.com/akanimax/Variational_Discriminator_Bottleneck
文責:馬場、西、宮川
まちなみ生成モデル実装:西
まちなみ写真収集・選別:宮川、水谷